 |
 |
 |
 |
| MT reshaping the language industry |
| 06 | Nástroje v Evropské unii a společnosti Oracle | |
|---|---|---|
|
|
|
|
| MT reshaping the language industry |
| 06 | Nástroje v Evropské unii a společnosti Oracle | |
|---|---|---|
|
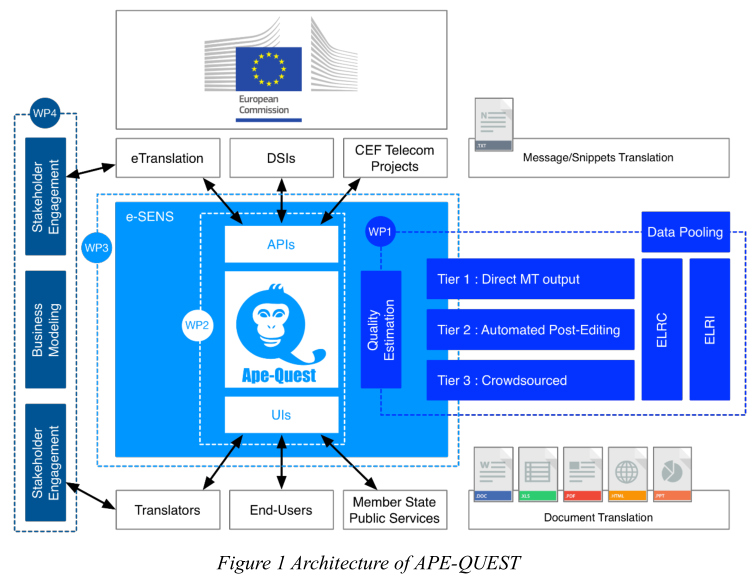
The APE-QUEST project (Automated Postediting and Quality Estimation) is funded by the EC’s CEF Telecom programme (Connecting Europe Facility, project 2017-EU-IA-0151) and
runs from October 2018 until September 2020.
The project provides a quality gate and crowdsourcing workflow for the eTranslation machine translation (MT) system. The latter system is developed by the Directorate-General for Translation, supports all 24 official EU languages, and is provided by the CEF Automated Translation building block 1 of the Directorate-General for Communications Networks, Content and Technology (DG CNECT) as a service to Digital Service Infrastructures (DSIs) of the EC and to public administrations of Member States. |
|
|
|
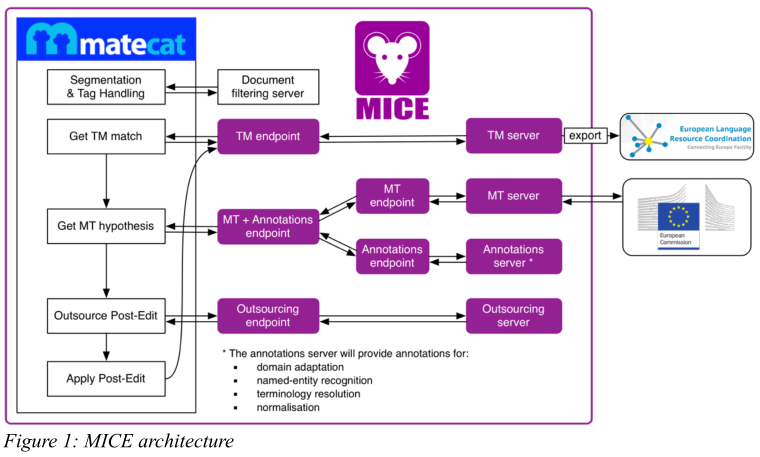
For example:
|
|
|
|
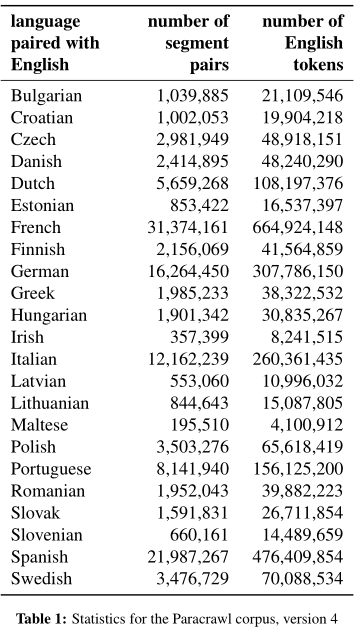
ParaCrawl: Web-scale parallel corpora for the languages of the EU An objective: to harvest parallel data from the Internet for languages used in the European Union.Namely, the first action focuses on parallel data between English and the other 23 official languages of the European Union, Poznámka: Evropská unie používá angličtinu jao hlavní komunikační jazyk. while the second one includes new pairs of languages, such as the pairs consisting of Spanish and the three regional languages recognized by Spain (Catalan, Basque, and Galician) or the two Norwegian languages (Bokml and Nynorsk). |
|
|
|
Volume 1: Research Track
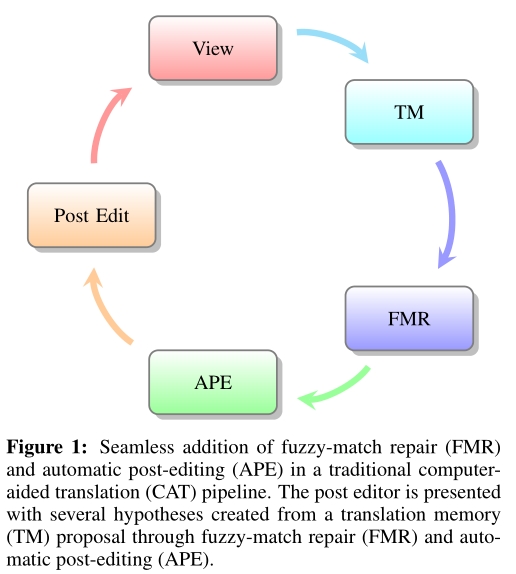
Oracle FMR is an automatic post-editing technique typically used with TM-based computer-aided translation (CAT) tools. In TM-based CAT, the translator is offered a translation proposal that comes from a translation unit (a pair of parallel segments) whose source segment is similar to the segment to be translated. In this paper, we show that APE could be used to improve sentence-level proposals from FMR when FMR is used as a device to create new translations from a TM. As shown in Figure 1, FMR is first used to produce a repaired translation proposal and then APE is used as a tool to improve the quality of the proposal. We demonstrate that the combination of these two techniques can significantly boost translation quality. |
|
|
|
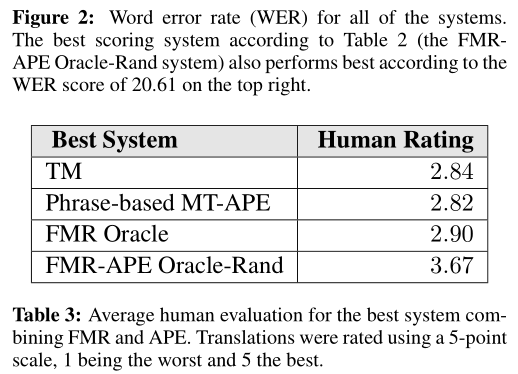
Table 3: Average human evaluation for the best system combining FMR and APE. Translations were rated using a 5-point scale, 1 being the worst and 5 the best. 10 Note that this strategy can be used in production because the used when a good-enough translation unit is not found. Nonetheless, the best scoring systems are the FMR-APE combination systems. |
|
|
| FMR Oracle. The best FMR was not immune to issues either. This could be due to the MT systems used. Many of the errors were similar to the Phrase-based MT-APE system; however, other errors were reported such as “punctuation is weird” and “important” words are missing. However, in more cases than others, it seems that the “FMR Oracle” system gets the underlying meaning correct. | FMR-APE Oracle-Rand. This system performed the best in all cases. We consider this to be the most important ?nding of this paper. While there were comments concerning UNK symbols (typical of the phrase-based MT translations), we saw some issues of morphology such as problems with in?ection. For the most part, the evaluator made few comments because the translations were easier to understand than all other systems. | |
|
(My note: CAT threshold for fuzzy match for TM is 75%)
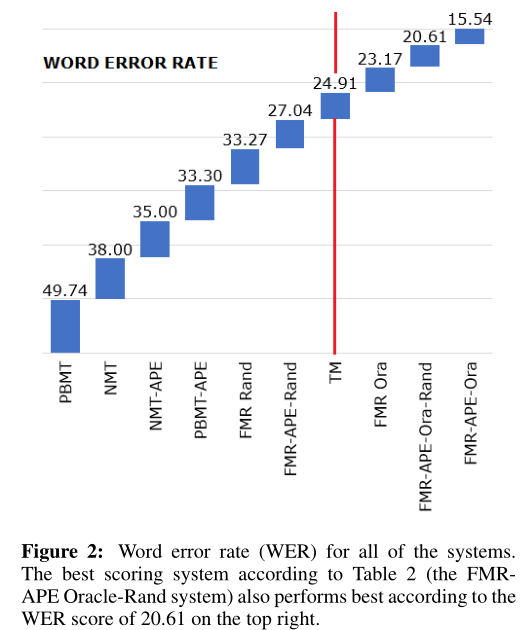
Figure 2: Word error rate (WER) for all of the systems. The best scoring system according to Table 2 (the FMR-APE Oracle-Rand system) also performs best according to the WER score of 20.61 on the top right 5.2 Human-based analysis The three measurements (BLEU, TER, and WER) show how well our best system performs and would probably be enough to show that it is worthwhile to combine FMR with APE. |
|
|
| Svoboda výběru pracovního postupu | překladatelé v některých orgánech mají možnost si zvolit jakým způsobem budou pracovat. Výsledky malého výzkumu diktování jsou na následující stránce. |
|
|
|
|